Dalam mempelajari data sains, hal paling utama ada visualisasi. Bagi saya satu chart saja bisa membuat saya memahami bagaimana konsep dasar dari sebuah model. Untuk praktik lapangannya, tentu saja kita dapat menggunakan dataset riil yang dapat diunduh dari berbagai bank data seperti kaggle, atapdata, dll.
Namun untuk pembelajaran dasar, saya lebih suka menggunakan dataset yang saya generate sendiri, karena memberikan fleksibilitas model terhadap dataset tersebut. Untuk meng-generate data tersebut bisa menggunakan library numpy dengan fungsi seperti random, namun ada cara yang lebih mudah yaitu menggunakan library scikit-learn (penulis menggunakan versi 1.3.1).
Dibawah ini terdapat 5 jenis dataset generator pada scikit-learn yang sering saya gunakan:
from sklearn.datasets import make_classification
from sklearn.datasets import make_regression
from sklearn.datasets import make_blobs
from sklearn.datasets import make_moons
from sklearn.datasets import make_circles- make_classification: membuat dataset acak dimensi N
code
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
# Buat dataset
X, y = make_classification(
n_samples=200, # jumlah data
n_features=2, # jumlah fitur (biar bisa dipetakan ke 2D)
n_redundant=0, # fitur redundan
n_informative=2, # fitur informatif
n_clusters_per_class=1,
random_state=42
)
# Plot hasilnya
plt.figure(figsize=(7, 5))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap="coolwarm", edgecolor="k", s=70)
plt.title("make_classification dataset")
plt.xlabel("Fitur 1")
plt.ylabel("Fitur 2")
plt.show()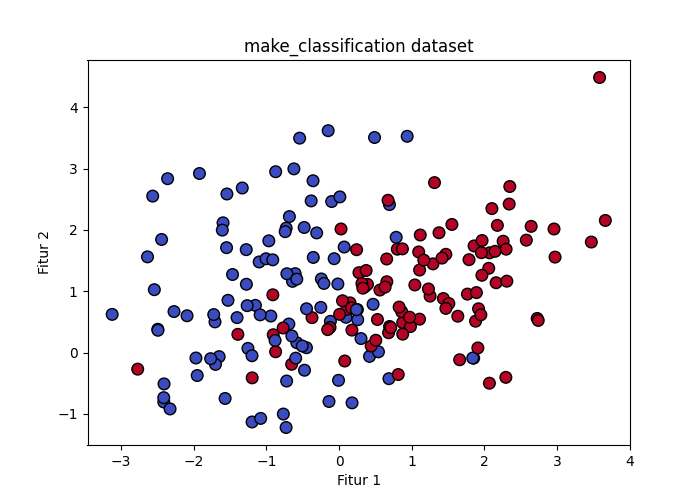
2. make_regression: membuat dataset acak regresi
code
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
# Buat dataset regresi
X, y = make_regression(n_samples=100, n_features=1, noise=15, random_state=42)
# Visualisasi dengan matplotlib
plt.scatter(X, y, color="blue", alpha=0.7, label="Data points")
plt.title("Contoh make_regression dataset")
plt.xlabel("Fitur X")
plt.ylabel("Target y")
plt.legend()
plt.show()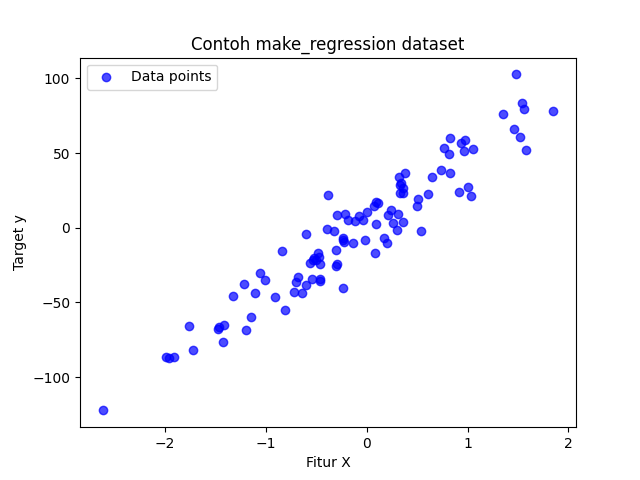
3. make_blob: membuat dataset cluster
code
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# Membuat dataset blob
X, y = make_blobs(
n_samples=300, # jumlah data
centers=3, # jumlah cluster
cluster_std=1.0, # standar deviasi tiap cluster
random_state=42 # supaya hasilnya konsisten
)
# Plot hasil blob
plt.figure(figsize=(8,6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', s=50)
plt.title("Contoh Dataset make_blobs")
plt.xlabel("Fitur 1")
plt.ylabel("Fitur 2")
plt.show()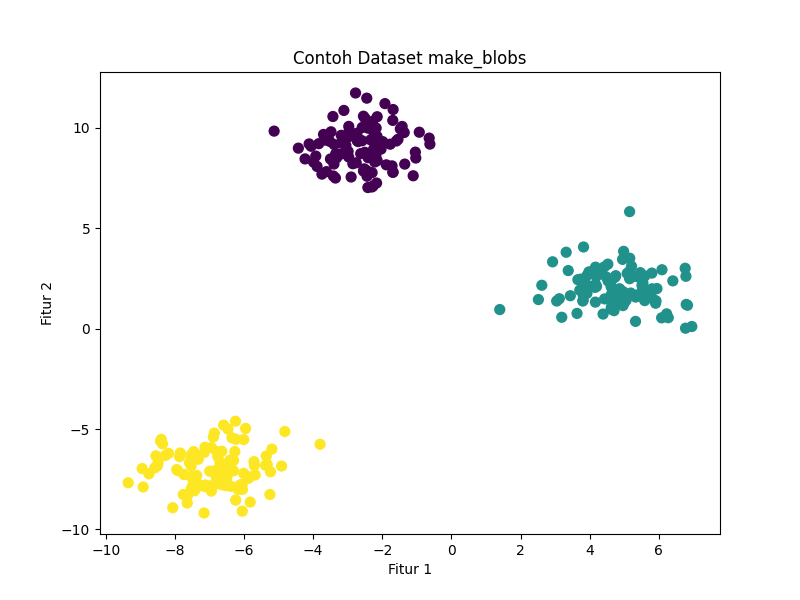
4. make_moon: membuat dataset berbentuk bulan sabit
code
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
# Membuat dataset moon
X, y = make_moons(
n_samples=300, # jumlah data
noise=0.1, # tingkat noise (acak)
random_state=42 # supaya hasil konsisten
)
# Plot hasil moon
plt.figure(figsize=(8,6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', s=50)
plt.title("Contoh Dataset make_moons")
plt.xlabel("Fitur 1")
plt.ylabel("Fitur 2")
plt.show()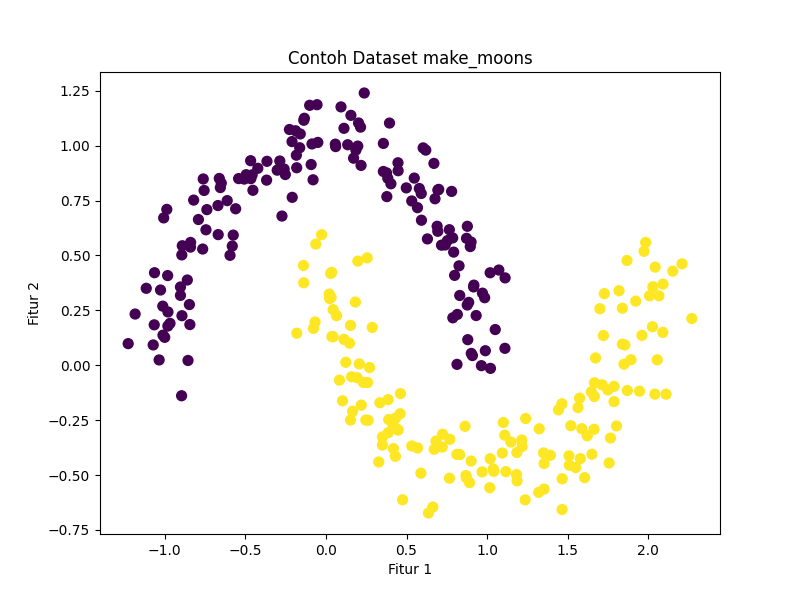
5. make_circle: membuat dataset berbentuk lingkaran
code
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
# Membuat dataset circle
X, y = make_circles(
n_samples=300, # jumlah data
factor=0.5, # rasio lingkaran dalam terhadap luar
noise=0.05, # tingkat noise (acak)
random_state=42 # supaya hasil konsisten
)
# Plot hasil circle
plt.figure(figsize=(8,6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', s=50)
plt.title("Contoh Dataset make_circles")
plt.xlabel("Fitur 1")
plt.ylabel("Fitur 2")
plt.axis("equal") # supaya lingkaran tidak oval
plt.show()
Setiap dataset yang digenerate memiliki beberapa parameter penting yang bisa diutak-atik untuk mendapatkan hasil yang lebih beragam, diantaranya:
- n_samples = n
ini merupakan fitur paling penting untuk menentukan banyaknya data n yang akan digenerate, jika n: 1000, maka ada 1000 dataset yang digenerate - n_features = n
ini merupakan fitur untuk menentukan banyaknya fitur / variabel / parameter / kolom pada dataset, biasanya saya memasukan nilai 2, karena lebih mudah memvisualisasikannya dalam grafik 2d. - random_state = n
ini merupakan fitur untuk menentukan status acak dataset, misalnya jika saya menaruh nilai 1 maka, dataset akan memiliki nilai yang sama setiap kali dataset digenerate, namun jika dirubah menjadi 2, maka nilai dataset yang digenerate akan berbeda dengan nilai 1. Apabila random_state dihilangkan, setiap kali menggenerate dataset, maka nilainya akan berbeda-beda. - noise = f
ini merupakan fitur untuk membuat setiap dataset yang digenerate akan memiliki sebaran data yang lebih besar. Misalnya jika noise = 0.1 dan 0.5, maka dataset dengan noise 0.1 akan lebih rapat, sedangkan noise 0.5 akan nampak lebih renggang satu sama lain. - cluster_std = f
Menurut saya ini mirip seperti noise, std merupakan standar deviasi dataset, jika nilainya semakin besar maka rata-rata data akan memiliki sebaran yang lebih besar.

